SiFive Intelligence X280数据手册和详细解读
时间:2025-04-10 | 栏目:处理器/DSP | 点击:次
作为RISC-V生态中首款面向高性能AI/ML场景的处理器IP,SiFive Intelligence X280通过开放架构、多引擎协同设计及灵活的扩展能力,成为数据中心、边缘计算和汽车电子等领域的创新解决方案。以下从技术架构、核心特性、应用场景及行业影响四个维度展开分析:
*附件:x280-datasheet.pdf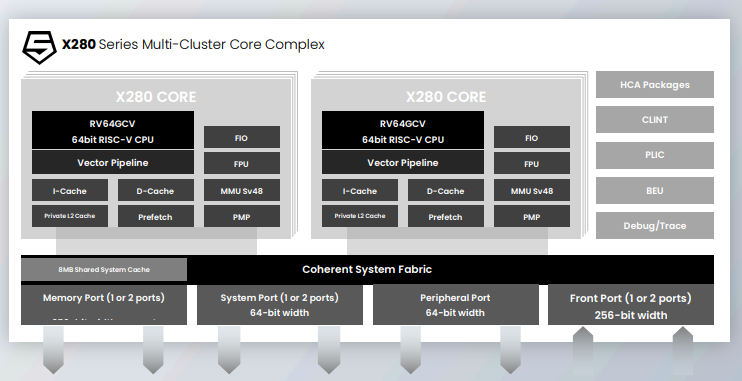
一、技术架构与核心特性
- 多引擎协同计算架构
X280采用 标量(RV64GC)、矢量(RVV 1.0)、矩阵(MXU)三引擎融合设计 ,支持混合精度运算(INT8/BF16/FP16)。标量引擎处理控制逻辑,矢量引擎执行并行计算,矩阵引擎加速深度学习中的矩阵乘法。通过 VCIX(矢量协处理器接口扩展) ,外部加速器可直接访问X280的矢量寄存器文件,实现低延迟数据交互(仅需数十周期),避免传统PCIe或内存传输的瓶颈。 - 可扩展性与内存优化
• 多集群架构 :支持16核缓存一致集群(Cache-Coherent Complex),单集群提供1TB/s持续内存带宽,并可通过CHI协议扩展至多集群,满足大模型推理需求。
• 高效缓存设计 :私有L1/L2缓存与共享L3缓存结合,优化数据流管理,减少冗余内存访问。例如,在MobileNet推理任务中,X280的智能扩展指令可实现标量ISA的144倍加速。 - 安全与软件生态
• WorldGuard可信执行环境 :提供ASIL-D级功能安全支持,适用于汽车电子等高可靠性场景。
• 开源软件栈 :兼容PyTorch/TensorFlow框架,集成SiFive Kernel Library(SKL)和OpenXLA PJRT Runtime,简化异构加速器编程。
二、性能表现与能效优势
• 算力密度 :单核性能达4.5 SpecINT2k6/GHz(HiPerf配置),支持每GHz 16 TOPS(INT8)或8 TFLOPS(BF16),适用于高吞吐量边缘推理。
• 能效比 :相较传统GPU,X280在同等算力下功耗降低30%以上,尤其适合自动驾驶和物联网设备的低功耗需求。
• 灵活性 :支持动态矢量长度调整(512位寄存器可组合至4096位),优化长向量运算效率,降低芯片面积与功耗。
SiFive Intelligence
X280 Key Features
- SiFive Intelligence Extensions for ML workloads
- Custom instructions to greatly accelerate Neural Network computation
- Optimized TensorFlow Lite implementation
- Hundreds of Neural Network models ported
- 4.6 TOPS performance
- 512-bit vector register length processor
- Variable length operations, up to 512-bits of data per cycle
- Ideal balance of control logic and data parallel compute
- Decoupled Vector pipeline
- INT8 to INT64 integer data type
- BF16/FP16/FP32/FP64 floating point data type
- Performance benchmarks
- 5.75 CoreMarks/MHz
- 3.25 DMIPS/MHz
- 4.6 SpecINT2k6/GHz
- Built on silicon-proven U7-Series core
- 64-bit RISC-V ISA
- 8-stage dual-issue in-order pipeline
- Coherent multi-core, Linux capable
- High performance vector memory subsystem
- Memory parallelism provides cache miss tolerance
- Virtual memory support with precise exceptions
- Up to 48-bit addressing
- Multi-core, multi-cluster processor configuration, up to 8 cores
三、应用场景与典型案例
- 数据中心AI加速
谷歌采用X280作为TPU的配套管理节点,通过VCIX接口连接自研MXU(脉动矩阵乘法器),实现AI负载的灵活分配。X280负责运行Linux系统和管理代码,MXU加速核心计算,两者协同提升大语言模型(如Llama)的推理效率。 - 边缘计算与消费电子
• 智能摄像头/AR设备 :X280的矢量单元可实时处理图像识别与语音交互,例如在MobileNet任务中实现24倍于标量架构的加速。
• 汽车电子 :车规级X280-A版本支持ADAS系统的实时目标检测,符合ISO 26262 ASIL-D标准,已被多家Tier 1供应商采用。 - 异构计算平台
X280与SiFive P系列CPU(如P870)组成混合架构,对标Arm big.LITTLE设计,适用于数据中心的高效任务调度与能效优化。
四、行业影响与未来趋势
- 挑战传统架构垄断
X280的开放生态吸引谷歌、特斯拉等企业替代NVIDIA GPU或Arm方案。例如,谷歌放弃自研TPU管理核心,转而采用X280+VCIX架构,节省开发周期并提升灵活性。 - 推动RISC-V进入高性能市场
此前RISC-V多用于MCU场景,而X280通过矢量扩展与多核集群设计,将应用扩展至数据中心和自动驾驶,缩小与x86/Arm在高性能计算领域的差距。 - 生态合作与标准化
SiFive与谷歌合作推进RISC-V对Android的兼容性,同时参与制定RISC-V UEFI、SBI等规范,加速生态成熟。
总结
SiFive Intelligence X280凭借开放架构、多引擎协同、高能效比三大核心优势,成为RISC-V生态冲击AI芯片市场的里程碑产品。其与谷歌TPU的深度整合、车规级安全特性及灵活扩展能力,不仅验证了RISC-V在高性能场景的可行性,更推动了从边缘到云端全栈AI计算的范式革新。随着生成式AI与自动驾驶需求激增,X280或将成为下一代异构计算平台的关键组件。