"Source Code Summarization in the Era of Large Language
时间:2025-09-18 | 栏目:大模型 | 点击:次
介绍
(1) 发表:ICSE'25
(2) 背景
之前的研究表明,与传统的代码摘要模型相比,LLM 生成的摘要在表达方式上与参考摘要有很大不同,并且倾向于描述更多的细节。因此,传统的评估方法是否适合评估 LLM 生成摘要的质量仍然未知
(3) 贡献
受到 NLP 工作的启发,本文对使用 LLM 本身作为评估方法的可能性做了全面的探索研究(不同 LLM/提示/设置,不同类型的语言)
工作
(1) 代码总结及其有效性评估的一般流程
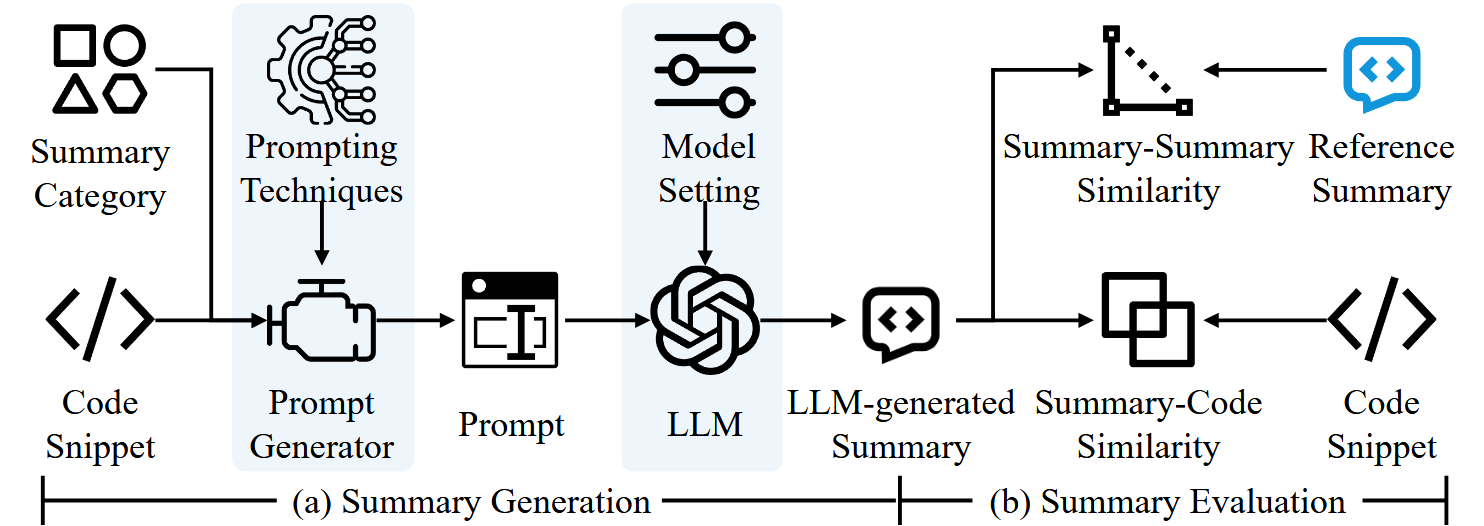
(2) 研究设计与分析
-
RQ1:哪些评估方法适合评估 LLM 生成的总结质量?
实验并分析了以下五种评估方式:
-
基于摘要之间文本相似度的指标:将生成摘要中的 n-gram 计数与参考摘要进行比较(包括 BLEU、METEOR 和 ROUGE-L)
-
基于摘要之间语义相似度的指标:基于语义相似性的方法可以有效缓解基于单词重叠的指标问题,即句子中并非所有单词都具有相同的重要性,并且许多单词具有同义词(包括 BERTScore、SentenceBert 与余弦相似度SBCS、SentenceBert 与欧几里得距离 SBED)
-
基于摘要与代码的语义相似度的指标:这种评估方法不依赖于参考摘要,可以有效避免与低质量和过时的参考摘要相关的问题(包括 SIDE)
-
人工评估:邀请具有软件开发经验的志愿者进行 1~5 评分并取平均分数
-
基于 LLM 的评估方法:与人类评估类似,当使用 LLM 作为评估者时,要求 LLM 进行 1~5 评分
得到了以下发现:
- 人工评估结果表明现有数据集的参考摘要的质量并不高
- 自动评估结果表明基于相似性的指标会给专业代码 LLM 更高的分数,基于 LLM 的评估会给通用 LLM 更高的分数
- 在所有自动化评估方法中,基于 GPT-4 的方法总体上与人类评估的相关性最强。因此,建议采用基于 GPT-4 的方法来评估LLM生成摘要的质量
-
-
RQ2:不同的提示技术在使 LLM 适应代码总结任务方面的效果如何?
分析了 Zero-Shot、Few-Shot、Chain-of-Thought、Critique、Expert 五种 Prompt 方式。预期性能更好的更高级提示技术不一定优于简单的零样本提示。在实践中,选择适当的提示技术需要考虑基本 LLM 和编程语言
-
RQ3:不同的模型设置如何影响 LLM 的代码总结性能?
Top_p 和 temperature 对生成摘要质量的影响特定于基础 LLM 和编程语言
-
RQ4:LLM 在总结用不同类型的编程语言编写的代码片段方面表现如何?
GPT-4 在所有五种类型的编程语言上都超过了其他三个 LLM,所有四个 LLM 在总结 LP (逻辑编程语言)代码片段方面表现较差
-
RQ5:LLM 在不同类型意图的总结上表现如何?
分析了五种不同意图类型的摘要:内容、原因、如何完成、属性、使用方法、其他。所有 LLM 都擅长生成不同类别的摘要,GPT3.5 和 GPT-4 在生成属性摘要方面的表现比其他类别的摘要差
总结
对基于 LLM 的代码总结评估进行了多个方面的全面研究,探究了 LLM 评估方法的有效性,并且公开了两个数据集