时间:2025-07-21 19:29
人气:
作者:admin
纳米酶传感器阵列是一种利用纳米酶的酶促活性同时区分多种物质的方法。与大型仪器不同,阵列检测通常能够在单次分析中区分多种目标物。纳米酶通常由金属中心和配体组成,并且常常表现出多种类酶活性,这使其能够对多种底物产生响应,并实现对多种底物的同时检测。然而,多种类酶活性的存在可能会导致干扰,进而降低检测过程的准确性。例如,过氧化物酶和过氧化氢酶都对底物H₂O₂有响应,氧化酶和过氧化物酶都对底物3,3',5,5'-四甲基联苯胺(TMB)有响应。因此,在检测目标物时,无法确定是哪种类酶活性导致了观察到的结果。所以,制备一种具有多种类酶活性、且能根据检测需要对单一底物产生特定响应的检测方法是一种有效的解决方案。
为了减少多种类酶活性带来的干扰,研究人员通常会改变外部环境或合成功能性纳米酶。例如,Guopeng Xu通过激光能量控制反应的能垒来激发不同的类酶活性。Guojian Wu合成了由多功能可视化分子印迹驱动的可切换活性纳米酶。Chu Wang通过用不同的手性配体修饰纳米酶实现了选择性检测。然而,由于检测时间和场地的限制,这种复杂的调控在食品的现场检测中可能并不适用。因此,开发一种能够展现多种类酶活性且能快速切换底物的纳米酶,对于食品分析至关重要。
茶多酚含有大量的酚羟基,这些酚羟基具有抗氧化和清除自由基的特性,因此与氧化还原反应密切相关。同时,茶多酚是茶叶中的重要活性成分,也是区分茶叶品质的关键指标。纳米酶的底物通常与氧化还原反应有关。因此,将茶多酚作为基于可切换底物纳米酶传感器阵列的检测目标具有重要的研究价值。通过改变条件,茶多酚和不同的氧化还原底物可以独立发挥作用,从而实现对茶多酚的精确区分,并进而评估茶叶品质。
设计原理
在这项工作中,我们利用ZIF-8模板合成了一种具有多种类酶活性的三金属纳米酶(CuMnZn)。该纳米酶被设计为在特定条件下对单一底物产生最佳响应,从而避免了多种类酶活性之间的相互干扰问题。如方案1所示,通过调节pH值,可分别在酸性、近中性和碱性条件下实现对三种底物的单一响应。在每个相应的pH条件下,该纳米酶能对各自的底物产生最佳响应,同时抑制对其他底物的响应。最后,基于茶多酚能对这三种底物产生响应的特性,我们将其应用于茶多酚的区分和检测。在机器学习的辅助下,我们能够在室温下短时间内(5分钟)100%准确区分二级和非一级产地的绿茶,具有良好的应用前景。
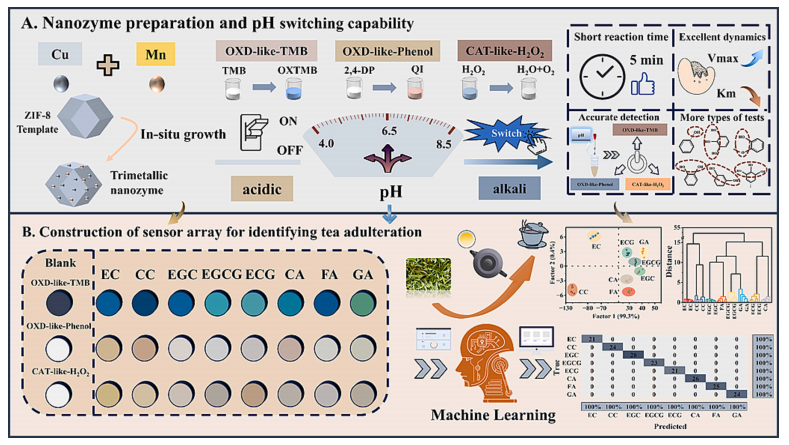
方案1.机器学习辅助的用于茶叶品类识别的可切换纳米酶反应阵列示意图。
数据介绍
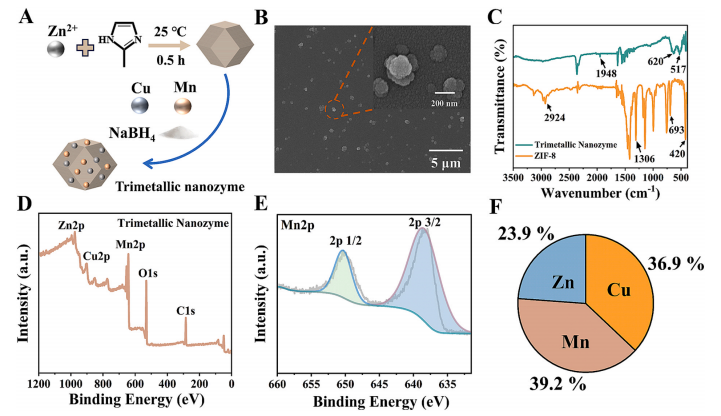
图1.三金属纳米酶的表征。(A)三金属纳米酶的制备过程。(B)三金属纳米酶的扫描电子显微镜(SEM)图像。(C)三金属纳米酶的傅里叶变换红外光谱(FTIR)。(D)三金属纳米酶的X射线光电子能谱全谱,以及(E)三金属纳米酶的Mn 2p光谱。(F)三金属纳米酶的元素含量比例。
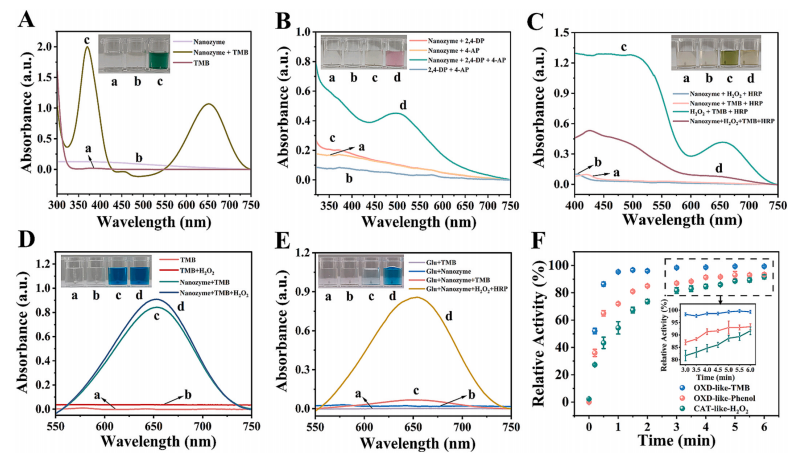
图2.纳米酶类酶活性研究。(A)类氧化酶活性。(B)类多酚氧化酶活性。(C)类过氧化氢酶活性。(D)类过氧化物酶活性。(E)类葡萄糖氧化酶活性。(F)反应进程与反应时间的关系。
研究观察到,三金属纳米酶对TMB(3,3′,5,5′-四甲基联苯胺)和酚类物质具有良好的氧化能力,并且能够催化分解过氧化氢(H2O2),同时受到其他类酶活性的干扰极小。如图2A所示,纳米酶氧化TMB的能力通过TMB从无色变为蓝色得以证明。如图2B所示,纳米酶氧化酚类的能力表现为无色的2,4 -二氯苯酚(2,4-DP)与4 -氨基吡啶(4-AP)结合后变为紫色。如图2C所示,纳米酶的类过氧化氢酶活性可通过其分解H2O2的能力得以证实,这使得在TMB和天然辣根过氧化物酶存在的情况下,反应体系不会显色。此外,研究还发现,在H2O2存在的情况下,纳米酶对TMB氧化能力的增强作用极小,这表明其类氧化酶活性优于类过氧化物酶活性(图2D)。茶叶中含有一定量的葡萄糖,为探究葡萄糖是否会干扰茶多酚的检测,研究对纳米酶氧化底物葡萄糖的情况进行了验证。结果发现,纳米酶几乎无法氧化葡萄糖生成H2O2,而H2O2会使TMB变蓝(图2E)。动力学数据表明,与传统纳米酶相比(表S1和S2),三金属纳米酶表现出较高的最大反应速率(Vmax)和较低的米氏常数(Km)(图S1)。结果显示,所有三种底物(TMB、酚类和H2O2)在5分钟时反应达到最大值(图2F)。这表明该纳米酶对底物具有强烈的响应。
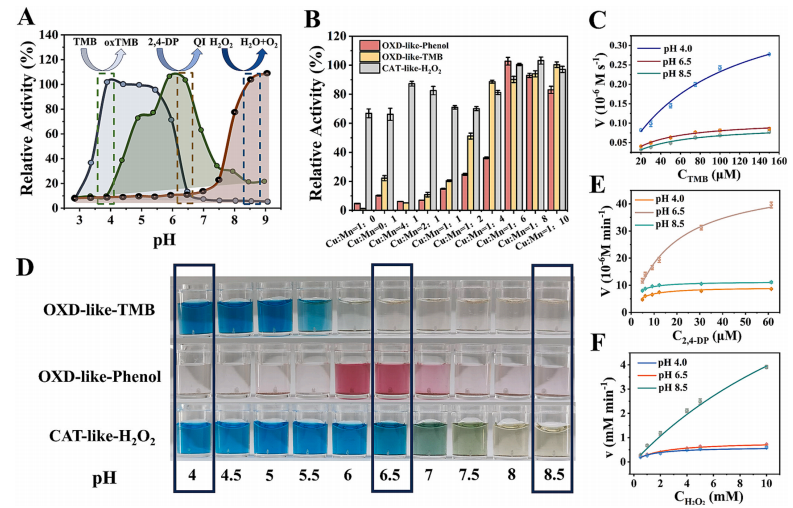
图3. (A)不同pH值对不同反应底物的影响。(B)制备比例对纳米酶活性的影响。(C)不同pH值下TMB底物的动力学表征。(D)三种纳米酶底物反应的实际图像。(E)不同pH值下2,4 -二酚(2,4-DP)底物的动力学表征。(F)不同pH值下H2O2底物的动力学表征。
为了在不同pH条件下实现对不同底物的特异性响应,研究人员探究了纳米酶在不同pH值下的活性。观察发现,三种底物(TMB、苯酚和H2O2)的响应明显依赖于pH值的变化。纳米酶对TMB的氧化作用主要集中在酸性条件下,在pH值为4时氧化能力最强,在接近中性时氧化作用消失。纳米酶对苯酚的氧化在中性条件下最为显著,在酸性和碱性条件下则明显减弱。相比之下,类过氧化氢酶活性仅在碱性条件下才能观察到(图3A)。利用图像的可视化表示有助于阐明底物反应的趋势(图3D)。值得注意的是,在每个pH转换条件下,相应底物的响应最佳,而另外两种底物的响应极小,从而确保了多种类酶活性检测的准确性。随后,对三金属的制备比例进行了优化,当比例为1:6时,纳米酶具有最佳的类酶活性和底物切换响应(图3B)。研究人员还探究了模板对纳米酶的作用。模板可以提高三金属纳米酶的分散性(图S2),当模板浓度(锌浓度)在0.02 - 0.1M时,类酶活性更强(图S3)。但只有在模板浓度为0.1M时,纳米酶才能实现底物切换的功能(图3D)。此外,该纳米酶还表现出出色的稳定性(图S4)和对常见离子的耐受性(图S5)。通过动力学分析研究了pH值对底物响应的变化情况。如图3C所示,在酸性条件(pH为4)下,纳米酶对底物TMB表现出优异的动力学性能,然而,在中性和碱性条件下改变TMB浓度时,TMB的氧化速率变化极小,导致动力学性能欠佳。同样地,纳米酶仅在pH为6.5(图3E)和8.5(图3F)时,对苯酚和H2O2表现出最佳动力学性能,在其他pH值下动力学性能会有所下降。
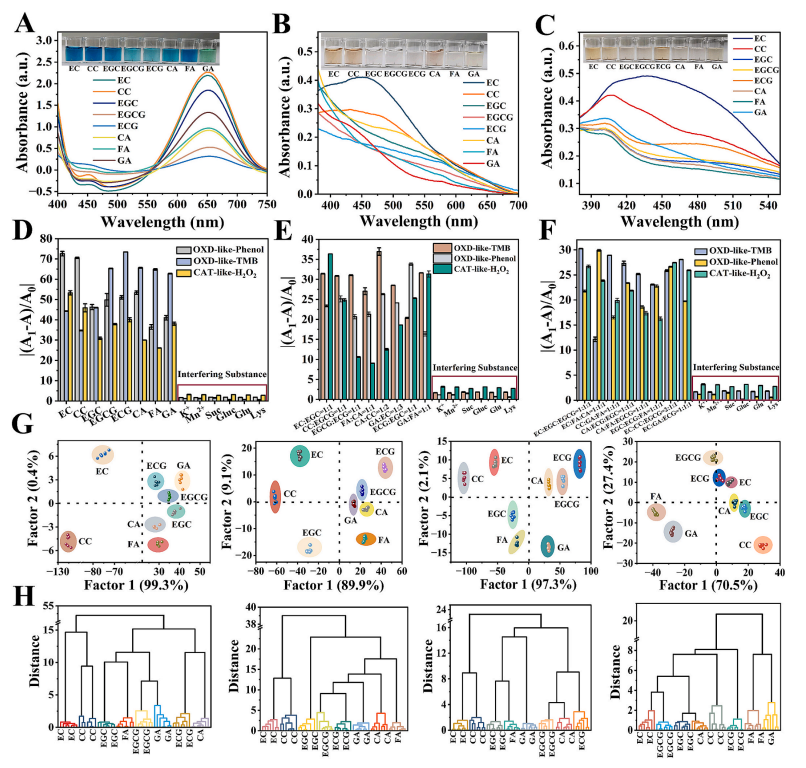
图4. (A)不同类型茶多酚对TMB显色抑制作用的影响。(B)不同类型茶多酚与纳米酶类多酚氧化酶活性的反应情况。(C)不同类型茶多酚对类过氧化氢酶活性的影响。(D)单一茶多酚组分的指纹图谱。(E)两种茶多酚混合物组分的指纹图谱。(F)三种茶多酚混合物组分的指纹图谱。(G)浓度为100、50、20和2 μM的茶多酚的线性判别分析(LDA)图。(H)浓度为100、50、20和2 μM的茶多酚的层次聚类分析(HCA)图。
不同的茶多酚因其酚羟基数量不同,具有不同的抗氧化能力。在此,我们以不同的茶多酚为底物,研究纳米酶与茶多酚之间的关系。此外,它们能与所有三种底物发生相互作用,这使得它们成为该检测方法的理想检测目标。如图4A、4B和4C所示,八种茶多酚对TMB显色的抑制作用各不相同,与4-AP结合后的显色情况也明显不同,并且对H2O2分解的抑制作用也有所差异。基于这些观察结果,我们设计了一种三通道纳米酶阵列检测方法,用于检测和区分不同种类的茶多酚。这三个通道在三种pH值条件下分别只对各自的底物产生响应,避免了干扰,确保了检测的准确性。
纳米酶反应在652nm、500nm和450nm处的吸光度值被用作区分八种茶多酚的依据。通过绘制不同茶多酚对三个通道响应的指纹图谱,我们能够深入了解它们之间的相互作用(图4D)。没食子酸(GA)和表没食子儿茶素(EGC)对TMB抑制和H2O2自由基清除通道的影响较大,这可归因于它们的邻三酚结构,这种结构赋予了它们显著的抗氧化和自由基清除能力 。在酚类显色通道中,表儿茶素(EC)和儿茶素(CC)由于其邻二酚结构易被氧化,因此会引发更明显的响应 。
在这三个通道中,茶多酚表现出不同的特征,而茶叶中的其他干扰物质没有响应,这表明以这种方式构建阵列来区分茶多酚是可行的。对浓度为100μM的数据集(3个传感器通道×8种茶多酚×6个平行样本)进行进一步的线性判别分析(LDA)表明,这八种茶多酚能够被有效区分,且相互之间没有重叠(图4G)。随后进行的无监督层次聚类分析(HCA)算法(图4H)显示,每种茶多酚也都能很好地聚为一类,这表明该阵列能够高精度地区分茶多酚。为了进一步验证传感器的性能,对低浓度(50、20、10、5和2μM)的样本也进行了区分,结果很成功(图4G、图S6A和图S6C)。在HCA算法下,所有样本也都能很好地分离并正确分类(图4H、图S6B和图S6D)。这使得传感器阵列能够区分浓度在2μM至100μM之间的任何茶多酚种类。此外,该传感器具有强大的抗干扰能力,能够100%准确地识别和区分多种常见的干扰物质(图S7)。考虑到茶多酚成分的内部变异性,制备了一系列随机混合的茶多酚,以模拟天然样品中的复杂性。我们进一步使用二元和三元混合茶多酚样品(图4E和4F)验证了传感器的性能,发现这些样品能够100%被区分开(图S8A和S8C),并且通过层次聚类分析(HCA)算法能够正确分类(图S8B和S8D)。这表明,这种可切换底物的比色阵列在区分茶多酚方面具有出色的能力。
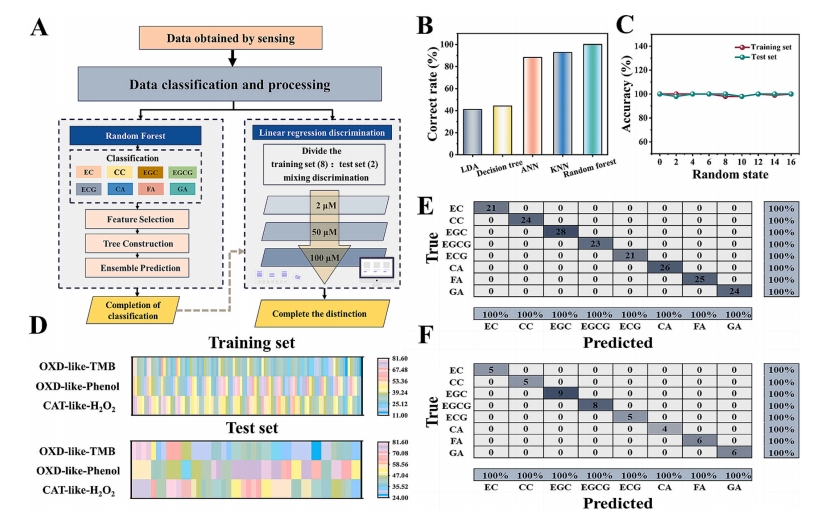
图5. (A)判别分析模型流程图。(B)几种算法正确率的比较。(C)随机种子与正确率之间的关系。(D)随机划分的训练集和测试集的热图。(E)随机森林处理后训练数据的混淆矩阵,以及(F)测试数据的混淆矩阵 。
鉴于真实茶叶样品中各种茶多酚的浓度各不相同,研究如何在忽略这些浓度差异的情况下区分茶多酚是一项有价值的工作。通过比较多种算法的准确性,随机森林模型被确定为区分效果最佳的模型,它能够实现100%的区分度(图5B)。随机森林算法是一种基于集成学习的机器学习算法,它通过结合多个决策树的预测结果来提高模型的准确性和稳健性。多个决策树的构建增强了传感器阵列的泛化能力。进一步的研究表明,随机种子的选择会影响区分的准确性。因此,本研究选择4作为随机数(图5C)。将同一种茶多酚的所有浓度样本归为一组,最终得到了包含八个标签的数据集。该数据集按照8:2的比例被划分为训练集和测试集,目的是在忽略浓度影响的情况下进行区分(图5A)。一般的流程是使用划分好的训练集构建模型,然后将其应用到测试集中,以评估模型准确区分的能力。该模型能够从输入的训练集中自动学习,并100%准确地区分所有样本。数据在模型的对角线上聚集,这表明模型的真实值与预测值是一致的(图5E)。测试集中100%的区分度也证实了这一点,这证明了模型构建的准确性(图5F)。色差图更直观地展示了不同类型茶多酚在不同浓度之间的差异(图5D)。总之,随机森林模型在不考虑浓度的情况下区分样本时,准确性有了显著提高,这有利于区分更复杂的样本模型。
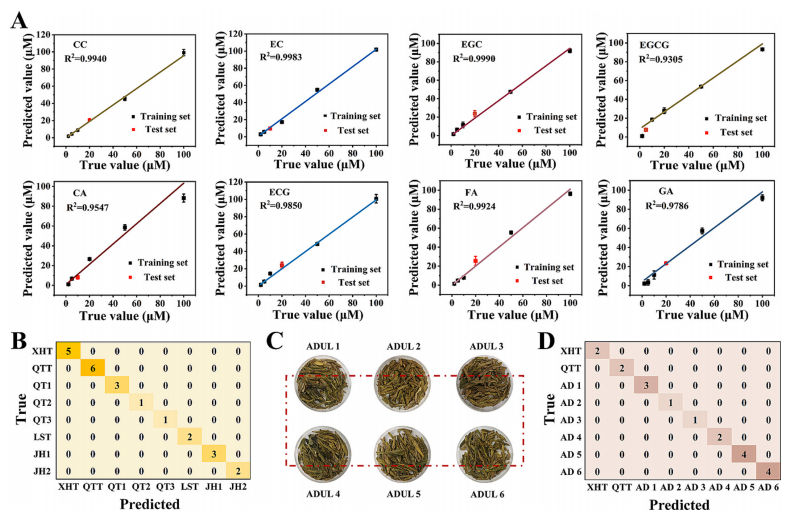
图6. (A)八种茶多酚的线性回归分析。(B)茶叶品种的随机森林判别结果。(C)掺假茶叶品种的实物图。(D)掺假茶叶品种的随机森林判别结果。
通过成功忽略茶多酚的浓度差异,我们再次实现了对多种茶多酚的回归定量预测,这使得该传感器阵列在实际样品检测中展现出卓越的区分能力。首先,利用最小二乘线性回归模型对八种茶多酚进行了定量分析,这有助于更详细地分析茶叶样品。每种茶多酚的预测值与真实值之间的线性关系具有高度相关性(R²值超过0.93),并且测试集的数据与预测模型高度吻合(图6A)。为了评估传感器阵列在实际环境中的适用性,我们选取了多种不同产地和质量等级的市售绿茶进行分析。每种茶叶取0.5克,加入20毫升纯净水,将溶液加热至80℃并保持20分钟。冲泡后的茶汤用0.5毫米孔径的注射器过滤,然后稀释10倍。如图6B所示,这些样品能够被有效区分,即使存在几种常见物质,传感器阵列仍能实现100%的区分度。这表明该传感器阵列在实际应用中不仅具有出色的区分能力,还具备一定程度的抗干扰能力(图S9)。
最后,我们将非一级产地的普通茶叶混入一级产地的特种茶叶中(分别标记为AD1至AD6),模拟市场上常见的掺假样品。如图6C所示,红色方框表示人工掺假的不合格茶叶。仅通过外观特征很难辨别掺假样品,尤其是在没有专业仪器的情况下。然而,通过传感器阵列结合随机森林模型进行分析,可以直观地呈现区分结果,并高精度地识别出掺假样品(图6D)。这表明,基于具有可切换底物的三通道传感器阵列,并借助机器学习,该方法可用于复杂样品的分析,同时能够区分茶叶的产地和等级,具有广泛的潜在应用价值。
总结
总之,我们合成了一种具有多种类酶活性的三金属纳米酶,它在不同pH值下对单一底物表现出最佳响应,而对其他底物无响应。我们开发了一种精确的三通道比色传感器阵列,包含三种可切换的底物,即3,3',5,5'-四甲基联苯胺(TMB)、酚类物质和H₂O₂,该阵列具有抗干扰性。基于不同的抗氧化、氧化显色和抑制自由基的能力,该传感器阵列成功地对八种茶多酚进行了区分。同时,机器学习有助于区分与浓度无关的数据,这有利于复杂样品的识别并展现出抗干扰能力。此外,该阵列在实际样品中具有100%的识别能力,能够区分掺假来源和等级的茶叶样品。纳米酶不仅具有多种类酶活性,还具备切换底物响应的能力,这有助于实现无干扰检测。这些研究结果对功能性纳米酶的制备及其在传感器阵列中的合理应用具有重要意义。
来源:微纳传感
https://doi.org/10.1016/j.cej.2025.162447
上一篇:如何选择酒精传感器

https://file.elecfans.com/web1/M00/82/2B/pIYBAFw2-D


 关注微信
关注微信