"AgenTracer: Who Is Inducing Failure in the LLM Agentic
时间:2025-09-08 | 栏目:大模型 | 点击:次
介绍
(1) 发表:Arxiv 09.03
(2) 背景
查明对长执行跟踪链路中错误负责的特定代理或步骤被定义为代理系统故障归因的任务。然而,当前最新的推理 LLMS 仍不为此挑战而明显不足,精度通常低于10%
尽管现有工作已经作出了初步尝试,但他们仍然存在实质性的研究差距:① 培训资源(涉及大规模注释的多代理轨迹的自动构建) ② 方法论(开发迅速而准确的多代理故障归因器)
(3) 贡献
-
自动化管道:本文提出了AgenTracer,这是第一个用于注释多代理系统故障的自动化管道,通过反事实重播和程序化故障注入,构建了六个数据集的 2,000 多个高保真故障轨迹
-
故障归因方法:本文开发了AgenTracer-8B,这是一种专用于 LLM 代理系统的轻质故障归因方法
-
实证评估:实验表明 AgenTracer-8b 的故障归因效果最好,并且可以提升现有 MAS 的性能
方法
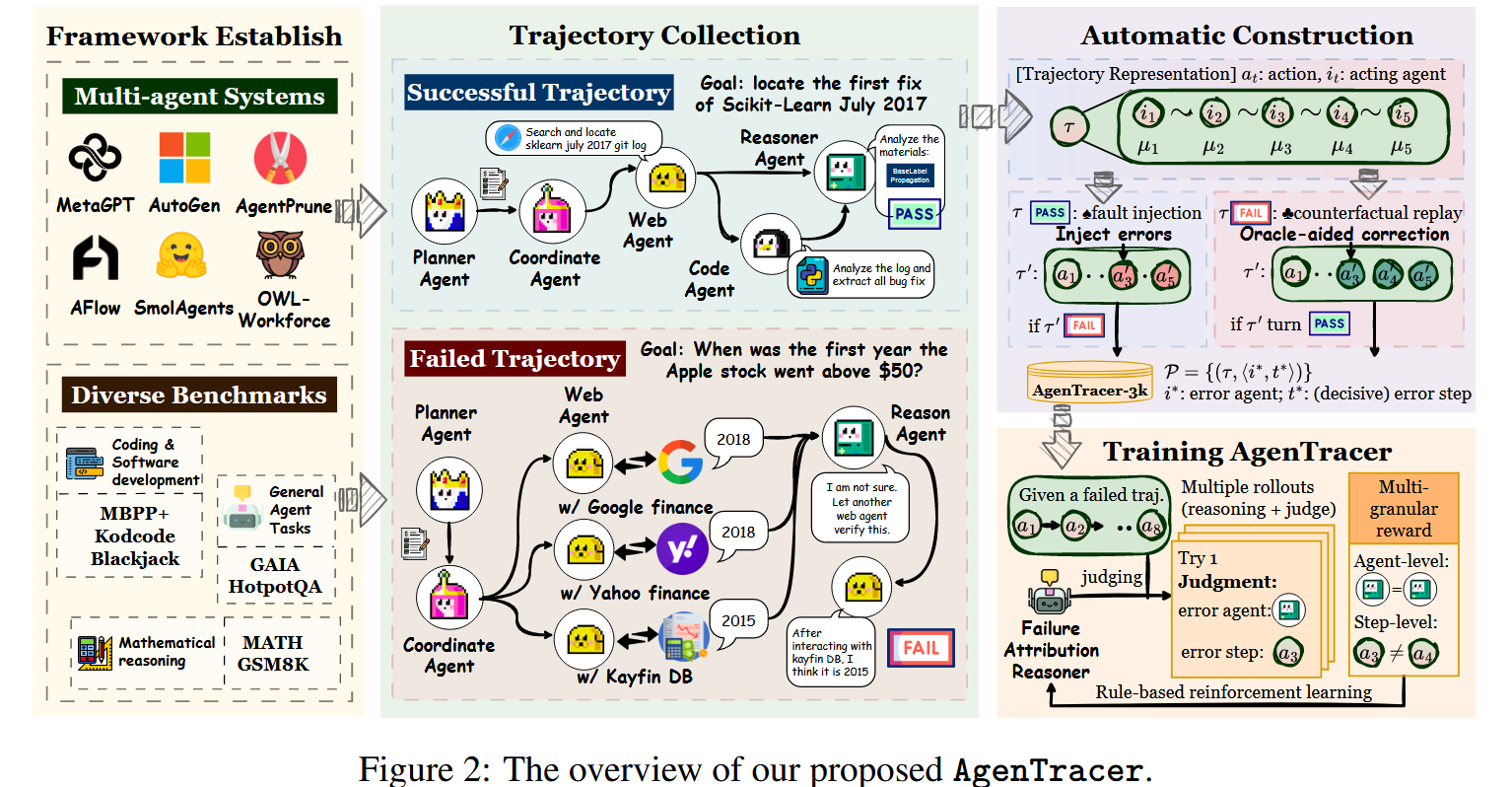
(1) AgenTracer: 自动化轨迹注释
-
数据收集:AgenTracer 首先考虑了 6 个不同的多智能体系统集合以及每个系统的相应查询集合,这些查询从不同的任务域中提取。对于每个查询,多智能体系统会产生原始轨迹,每个系统的轨迹分为成功和失败两组,作为后续注释阶段的原始输入
-
定位根因:分析器 Agent 进行反事实干预,对轨迹中的每个步骤 \(t\),分析器 Agent 都提出一个微创的矫正操作,纠正局部误差而不揭示完整的解决方案。通过对 \(t\in\{0,1,\cdots,T\}\) 依次操作,可以系统的搜索最早根因步骤 \(t\),此步骤中处于活动状态的代理被标记为有问题的代理,为我们的数据集生成精确的注释
-
利用成功的轨迹:对于成功的轨迹本文进行编程故障注入,核心原则是用已知良好的轨迹并以编程方式引入故障,从而创建一个综合故障实例,其中决定性错误通过构造已知
-
精选数据集:通过将失败轨迹和合成生成的轨迹得出的注释结合起来,我们构建了最终的综合数据集
(2) AgenTracer-8B: 训练代理故障归因器
整理完数据集后,继续训练代理故障归因器 AgenTracer-8B,其基础模型设置为 Qwen3-8B。这里基于一种广泛使用的在线 RL 方法,即群体相对策略优化(GRPO)进行实验
-
在线强化学习:对于每个轨迹,当前策略生成一组候选根因对,并根据 ground-truth 使用多维度奖励函数 \(R_k\) 进行评估 (具体定义省略)
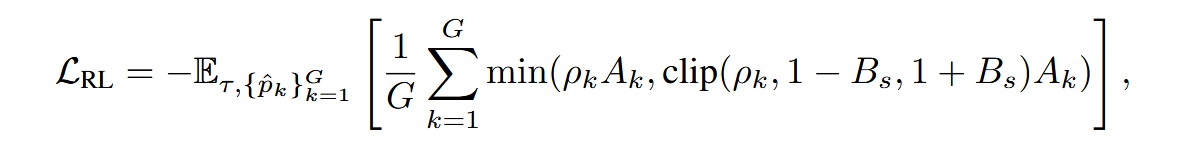
-
多粒度奖励设计:本文引入了一种多粒度奖励,只在评估归因的正确性和输出的结构完整性。总奖励 \(R_k\) 是内容准确性和格式合规性的门控组合
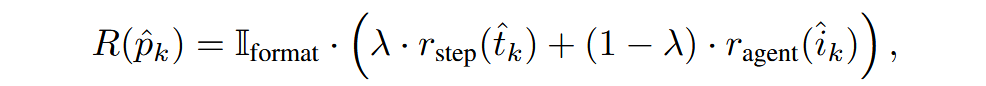
公式中的三个奖励函数:
format 格式奖励:二元奖励,衡量输出结构是否正确
agent 奖励:二元奖励,衡量是否正确识别故障代理
step 奖励:使用高斯核,其中奖励随着预测的步长远离根因步骤而衰减
通过这些设计的在线强化学习,我们得到了一个基于推理的多智能体故障归因器 AgenTracer-8B
实验
(1) 故障归因的表现
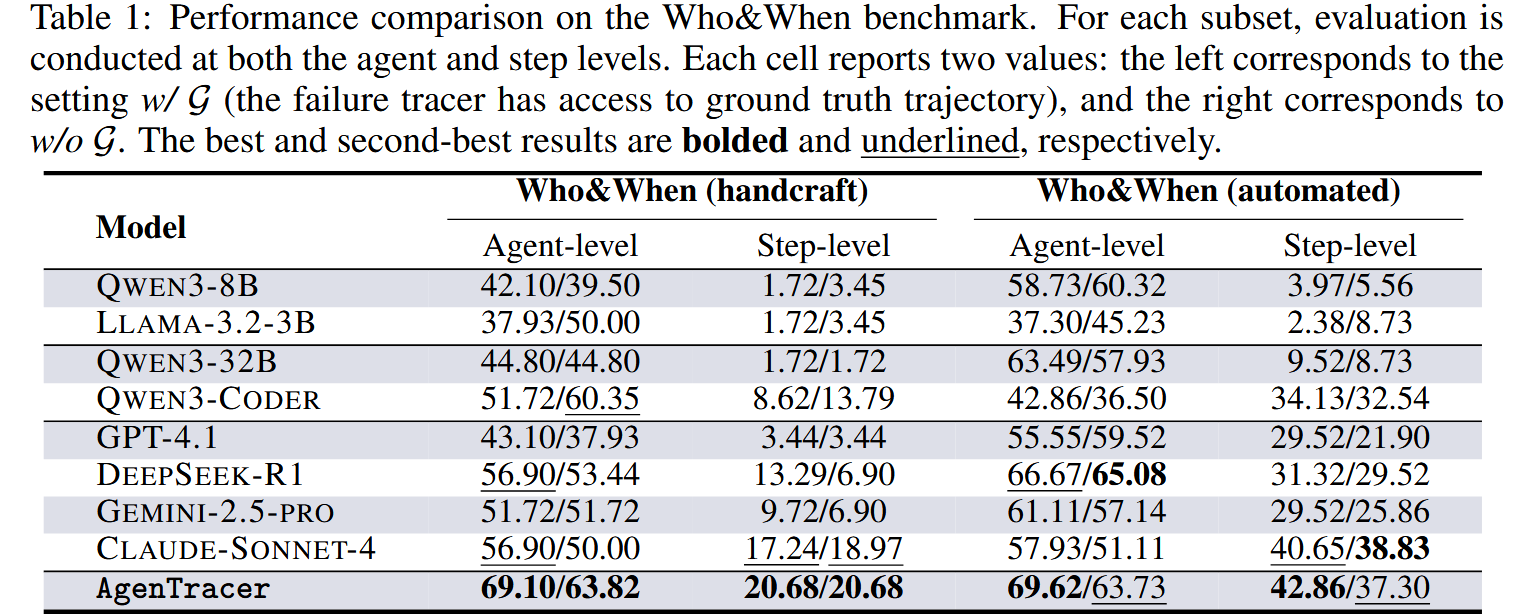
可以看到现有的先进 LLM 效果有限, AgenTracer-8B 用小参数基本上达到了最领先的效果
(2) AgenTracer 的实用价值
在确定了 AgenTracer 在故障归因方面的准确性之后,一个自然的问题就出现了:它提供了什么实用价值?最直接的答案是它有可能为失败的基于 LLM 的代理系统提供可作的反馈,从而实现快速的自我改进。为了评估这种能力,我们将 AgenTracer-8B 与两种经典的自我改进方法进行了比较
具体来说,当代理系统 M 完成一个解决问题的情节并产生一个失败的轨迹 τ 时,我们向 AgenTracer-8B 或 Self-Refine/CRITIC 提供 τ (w/o G)。然后,每种方法都会生成有关故障的反射反馈(对于 AgenTracer-8B,这对应于 ⟨think⟩ · · · ⟨/think⟩ 中提取的推理轨迹)。随后,在下一轮问题解决过程中,这些反馈被注入 M,目的是利用外部批评来提高其性能。我们将这个过程迭代了三轮,Self-Refine 和 CRITIC 都是使用 GPT-4.1 实例化的
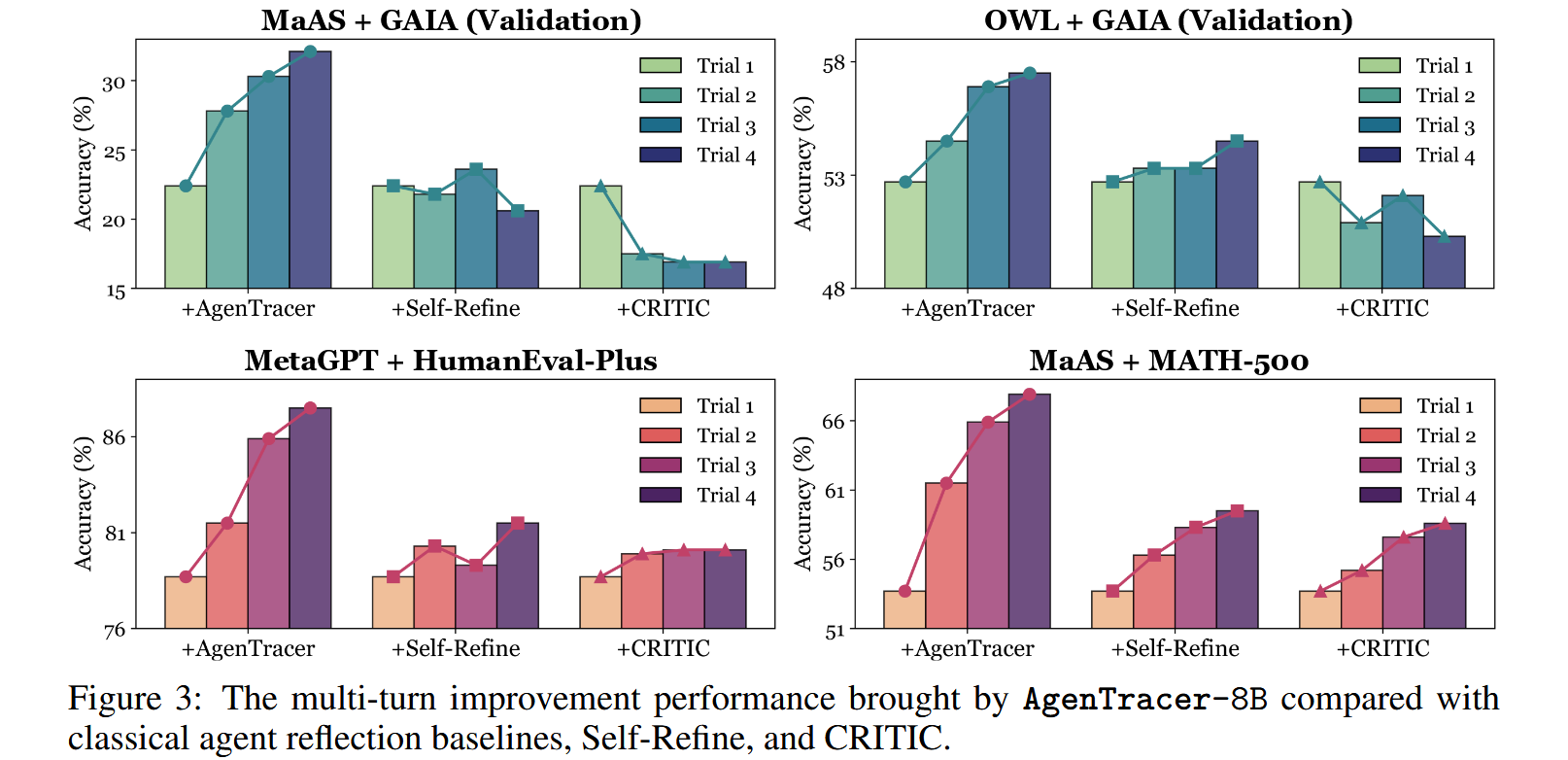
结论
这项工作为研究代理系统故障归因奠定了原则基础。AgenTracer 提供了第一个能够系统地生成带注释的故障轨迹的自动化框架,在实际多代理框架中部署时还能产生一致的性能提升(个人认为非常好的工作,解决了我对该方向的很多问题)