时间:2025-05-16 14:19
人气:
作者:admin
来源:老刘记事儿
最近有客户反映国产京微齐力P2器件内部合封的pS读写效率很高,能达80%以上,而且合封了4片8bit位宽pSRAM芯片,按250MHz主频双沿读写算下来80%效率能跑出12.8Gbps的极限带宽,即使考虑工程布局布线的限制影响因素,按210MHz主频也应能跑出10.bps读写带宽。
如果真是这样,这意味着FPGA + RAM架构方案的市场应用生态位面临着挑战,因为即使采用200MHz主频的单颗DDR SDRAM也需要32bit位宽才能在理论上达到100%效率时(不可能实现)的12.8Gbps极限带宽,而SDRAM控制器设计复杂度导致的逻辑资源消耗、SDRAM芯片较高的功耗特性、外挂SDRAM芯片的成本考量等因素会使FPGA + SDRAM架构方案劣于京微齐力的FPGA内部合封4片pSRAM方案。
那么真实情况如何呢?客户的传言是确切的么?
带着疑问,我要来了京微齐力P2器件的pSRAM读写例程,进行核实分析。
根据说明,该例程系统框图如下:
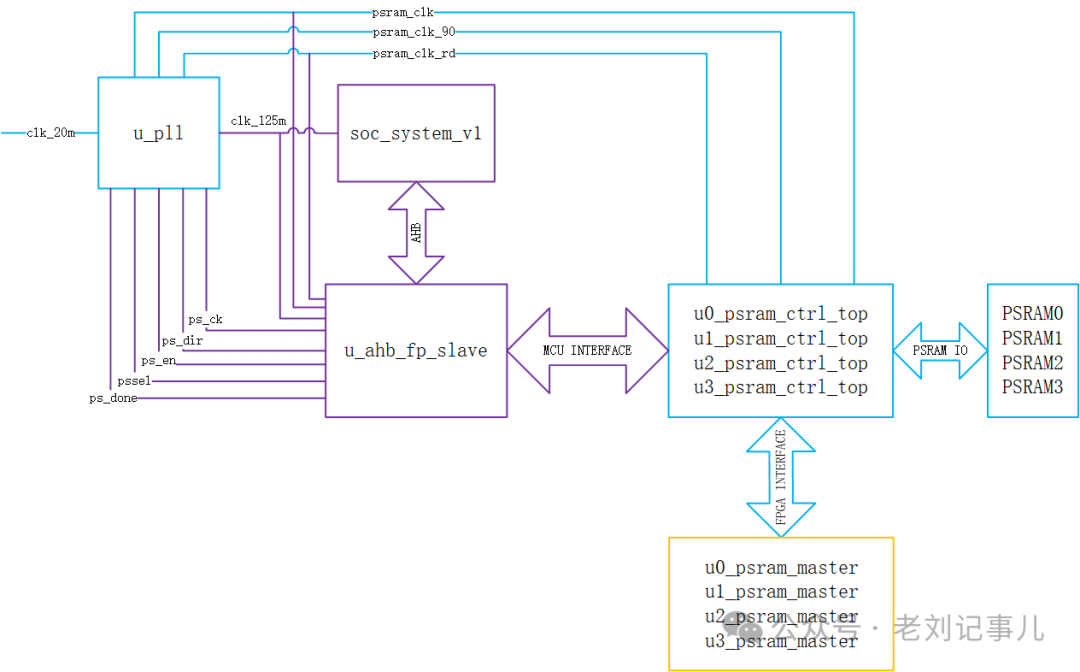
其中,soc_system_v1模块是指P2器件中自带的 Cortex-M3硬核,在例程中起到对pSRAM的初始化和Clock Trning作用。Clock Training是上电启动阶段指对psram_clk、psram_clk_90和psram_clk_rd这三个的相位关系进行初始化校准。这三个时钟的功能可参阅原厂手册说明(见下图),在此我们不作更多推敲讨论。

不过显然可以看出,将pSRAM初始化和Clock Training机制放进FPGA自带的ARM硬核中,对于节省FPGA逻辑资源占用肯定是很有好处的,而且在ARM硬核中实现对pSRAM寄存器状态和Training结果的打印监测也是十分方便的。原厂例程中就利用了这一点,下图为例程中ARM硬核控制pSRAM执行初始化和Clock Training阶段串口打印的部分信息,显示了Clock Training的时钟窗口扫描结果。
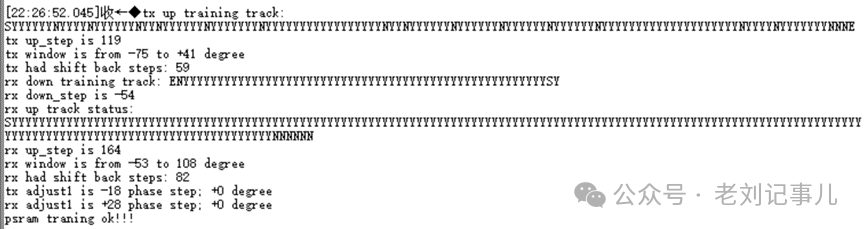
例程提供的pSRAM控制器可允许对4片pSRAM予以分别不同的寄存器初始化配置,使其分别独立工作在不同的工作状态下。这为客户提供了灵活操控的可能性,在必要的应用场合可以灵活搭配形成乒乓操作,譬如4片pSRAM可以配置成同时1写3读或3写1读,也可以4片统一同步操作读写。
例程配套有工程,可以直接从仿真波形中得到pSRAM读写效率信息。
仿真例程先是对4片pSRAM分别作了初始化配置动作,而后循环进行But 1~128次*2By的交替读写循环测试。

每次Burst写入pSRAM的数据会同步存入双RAM中,再将RAM中的数据取出与从pSRAM中相应地址读出的数据作一致性比对,如果读写比对无误则psram_cmp_flag保持为0,否则一旦发生错误就会拉高相应pSRAM的psram_cmp_flag信号。

对交替读写循环测试的波形放大可以看到,pSRAM的读写过程各有快慢两种响应速度,姑且称之为 “快写”、“慢写”、“快读”、“慢读”。
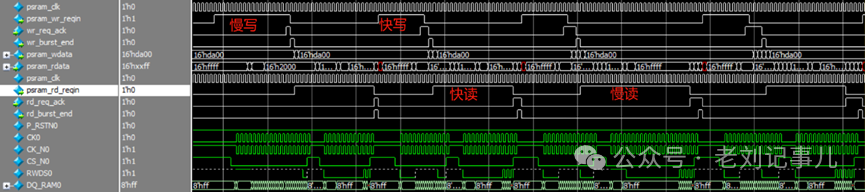
pSRAM写操作相关的FPGA端用户信号时序抓取波形示例如下:

pSRAM读操作相关的FPGA端用户接口信号时序抓取波形示例如下:

各路信号的含义和时序关系说明详情可参见官方应用手册,此处不作赘述。
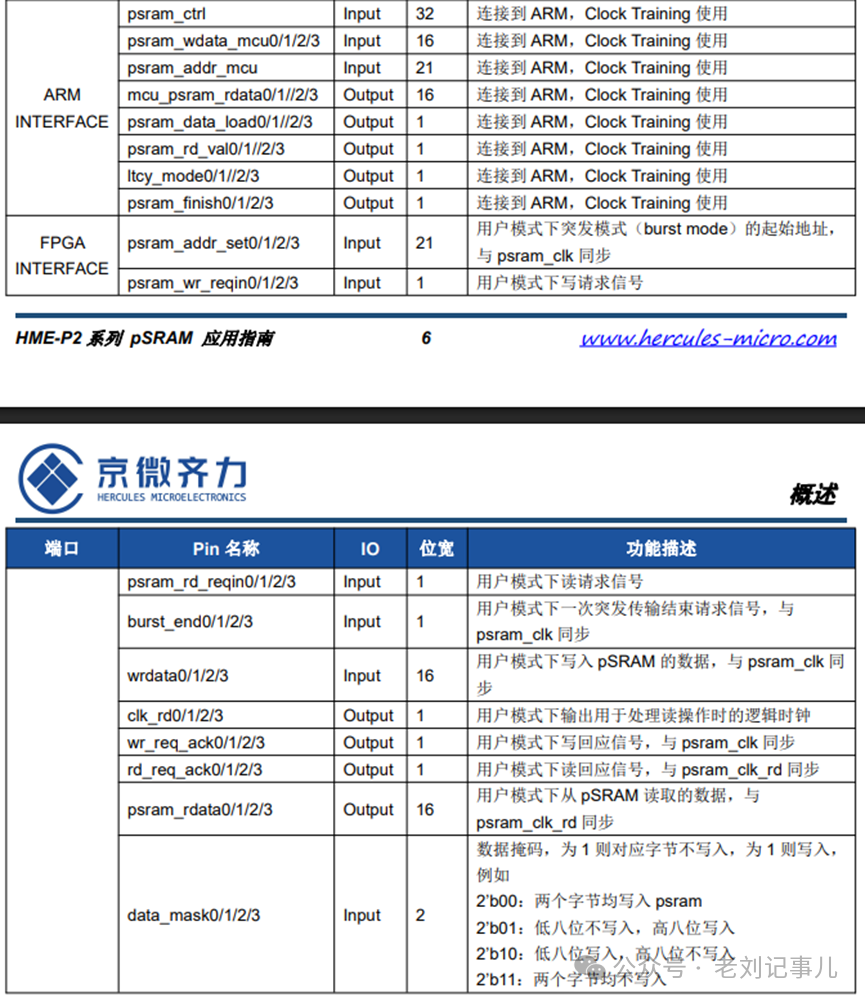
我们只关心读写效率的评估,那么把握重点:
psram_wr_reqin和psram_rd_reqin分别是写请求和读请求信号;
wr_req_k和rd_req_ack分别是写响应和读响应信号,其中wr_req_ack的高电平比psram_wdata写有效数据前移了一拍,而rd_req_ack的高电平与psram_rdata读有效数据是时序对齐的;
读写Burst长度分别由rd_burst_len和wr_burst_len决定,实际Burst拍数分别为rd_burst_len+1 和wr_burst_len+1。

对照仿真波形可以确认,例程中的pSRAM读写循环是无缝切换的,没有冗余间隔,因此psram_wr_reqin和psram_rd_reqin的高电平宽度分别就是写等待和读等待时长,即除有效读/写操作之外被“浪费”的时间。写等待和读等待时长所占用的时钟周期数分别称为写等待拍数和读等待拍数。
“快写”、“慢写”、“快读”、“慢读”分别的等待拍数见下表:
| 读写状态 | 快写 | 慢写 | 快读 | 慢读 |
| 等待拍数 | 11 | 18 | 19 | 26 |

“快写”状态下,从发起写请求到第一个有效数据开始写入,写等待占用了11个时钟周期。因此,当Burst为256字节(128拍)时写效率最高,为:
128/(11+128) =92%
对应P2器件工作在210MHz主频下的“快写”带宽为:
92%×210MHz×2×4片 ×8 bits =12.08 Gbps

“慢写”状态下,从发起写请求到第一个有效数据开始写入,写等待占用了18个时钟周期。因此,当Burst为2字节(1拍)时写效率最低,为:
1/(18+1) = 5.26%
当Burst为256字节(128拍)时,“慢写”效率为:
128/(18+128) = 87.6%
对应P2器件工作在210MHz主频下的“慢写”带宽为:
87.6%×210MHz×2×4片 ×8 bits
=11.5 Gbps

“快读”状态下,从发起读请求到第一个有效数据开始读入,读等待占用了19个时钟周期。因此,当Burst为256字节(128拍)时读效率最高,为:
128/(19+128) =87%
对应P2器件工作在210MHz主频下的“快读”带宽为:
87%×210MHz×2×4片 ×8 bits
=11.42 Gbps

“慢读”状态下,从发起读请求到第一个有效数据开始读入,读等待占用了26个时钟周期。因此,当Burst为2字节(1拍)时读效率最低,为:
1/(26+1) = 3.7%
当Burst为256字节(128拍)时,“慢读”效率为:
128/(26+128) = 83.1%
对应P2器件工作在210MHz主频下的“慢读”带宽为:
83.1%×210MHz×2×4片 ×8 bits
=10.9 Gbps
这样情况就明了了。也就是说:
京微齐力P2器件的pSRAM写操作在Burst长度为256字节(128拍)的条件下效率最高,为87.6%至92%之间。
保守估计,按210MHz的大型项目(逻辑资源占用80%以上)真实可用主频估算,在Burst长度为256字节(128拍)的条件下,其写带宽可达11.5 Gbps至12.08 Gbps之间。
京微齐力P2器件的pSRAM读操作在Burst长度为256字节(128拍)的条件下效率最高,为83.1%至87%之间。
保守估计,按210MHz的大型项目(逻辑资源占用80%以上)真实可用主频估算,在Burst长度为256字节(128拍)的条件下,其读带宽可达10.9 Gbps至11.42 Gbps之间。
当然,需要特别注意的是,由于存在内部自刷新过程,和SDRAM一样,pSRAM在Burst长度较低时,读写效率不高。但Burst突发读写长度越长,其读写效率越高,速度优势越明显。
总体而言,京微齐力FPGA的pSRAM读写效率,超出预期!
附P2器件(合封4片pSRAM)在不同Burst长度下的读写效率列表以供查阅(注意1拍对应2字节):




附在P2器件(合封4片pSRAM)在pSRAM主频210MHz条件下核算的不同Burst长度下的读写速率列表以供查阅(注意1拍对应2字节):




不过这里可以再引出一个问题:
快写/慢写(快读/慢读)的比例是多少,有何规律?
此处暂且不表,笔者搬砖之余时间有限,且听下回分解。

Fidus Sidewinder-100集成PCIe NVMe 控制系统,有
 关注微信
关注微信